
どうも、kotaro(@kotaronline)です。
Twitterなどをご覧になっていると、「My new gear...」なんて言葉とともに、新しく購入した機材の写真をアップしている方を見かけることも多いと思います。
かくいうぼくも、新年早々新しい機材を導入しました。こちらです。

え? ただのスカイプ用ヘッドセットじゃないかって?
そのとおりです(笑)。
この、何の変哲もないスカイプ用マイクを、どう使おうとしたのか、それはこれから説明します。決して、「これでボーカルを録音しよう」と思ったわけではないですよ(もしかしたら面白い音が録れるかもしれませんが)。
ちなみに、昨年末には、もう少しちゃんとした音楽機材も導入しております。

以前、借り物のウインドシンセを演奏したことがあるので、もう少し簡単に使えるかと思ったのですが、他人様に聴かせるレベルの演奏をするには、きちんとした練習が必要なようです。
こちらの導入でもドタバタがありましたので、そのうちブログ記事にするかもしれません。
それはさておき、本題の、スカイプ用マイク導入した理由の説明です。
現在構想中の曲で、どうしてもセリフを入れたくなりました。
諸々の事情により、特定のボーカロイドを使ってしゃべらせる必要があるのですが、残念なことに、ぼくにはいわゆるトークロイドの入力技術についてのノウハウがありません。というか、だいぶ前に解説サイトみたいなものを見たことがあるような気がするのですが、「こんな面倒くさいこと、よくやるなあ」と感心したものです。
面倒なことが嫌いで、面倒なことを回避するためにさらなる面倒を抱え込むこともあるぼくが考えたのは、「自分でしゃべった音声データを、DAWの機能でMIDIデータに変換して、それをボーカロイドエディターで読み込ませればいいんじゃないか?」というものでした。現在の制作環境は、「最初から最後までPC内部で作業を完結する」のに最適化されているため、マイクなどの入力機器は所持していません。そこで、「どうせ解析用の仮データだし、スカイプとかに使うお買い得な製品でも十分なんじゃないか?」と思ったわけです。
思いついたら早速実行。通販サイトでリサーチして、「2000円くらいで買えるのかな……」と思って見ているうちに、型落ちなのだかどうだか、500円台で売られている製品を発見しました。これで送料無料って利益出るのかな、と少しだけ心配になりましたが、そうは言っても懐にやさしいのはありがたいところ。迷わずそちらの製品を購入しました。
製品が届いたら早速実験です。使いたい言い回しはほぼ固まっているので、それぞれのセリフを個別に録音。メインで使っているSONAR改めCakewalk by BandLabに読み込みます。ここで活躍するのが、SONAR X3以降は付属しなくなってしまったV-VOCALです。
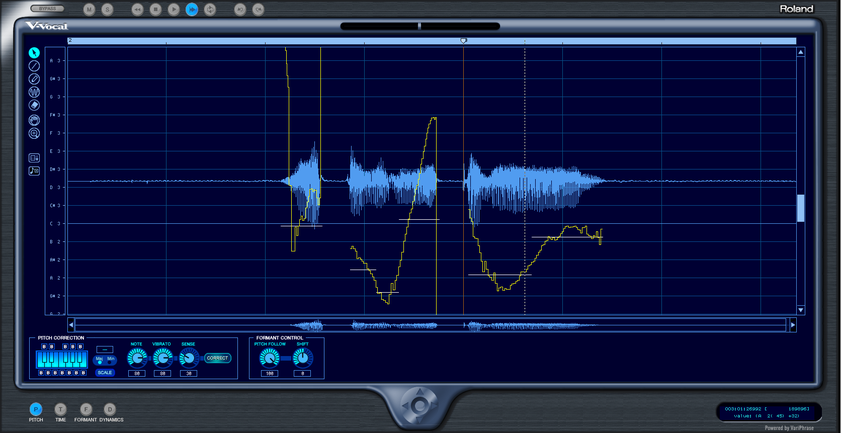
V-VOCALでしゃべり声を解析したところ。
左側にアイコンがずらっと並んでいますが、その一番下にあるのが、今回お目当ての、Pitch-to-MIDI機能です。
V-VOCALのPitch-to-MIDI機能のアイコン。
ここから、SONARもといCakewalk by BandLabのMIDIトラックにドラッグ&ドロップすることで、MIDIクリップが生成されます。
ちなみに、意外とご存じない方も多いのですが、SONARじゃなくてCakewalk by BandLabのMIDIクリップをエクスプローラーの任意の場所にドラッグ&ドロップすると、SMF(スタンダードMIDIファイル)が生成されます。
こうしてできたMIDIデータをボーカロイドエディターに読み込ませて、歌詞(?)を入力すれば一件落着……というほど甘い話でもなかったのですが、多少の調整は必要だったというありがちな話のほかに、試してみて気づいた話を少し。
V-VOCALの画面上で右クリックすると、ピッチベンドデータをどう扱うかの設定が出てきます。
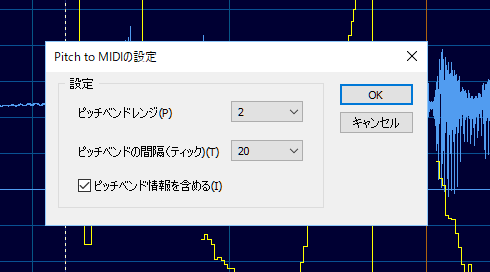
右クリックすると設定画面が出る。
最初、「ピッチベンドを利用した方が、イントネーションが自然に表現できるのでは?」と思いました。だって、これくらい細かくデータに繁栄されますからねえ。
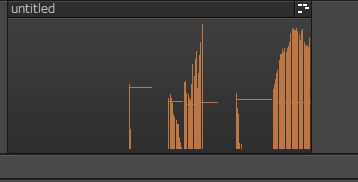
縦線で表現されているのがピッチベンド情報。
しかし、この方法だと、ボーカロイドエディターで発音情報を入力するとき、入力したい言葉に対して音符の数が少なくなってしまうことがあります。異なる音符として認識してほしいとこまで、ピッチベンドで表現されてしまうんですね。
そんなわけで、こういう使い方をする場合、ピッチベンドは使わず、全部ノート情報で処理させたほうがよい結果になりそうです。
あと、実際に何パターンか言い回しを試してみた結果、男声はまあまあ満足できるデータになったのですが、女声はどうも今一つな結果になりました。「MIDIデータにしちゃえば、あとはどうにでもなるだろう」と思ってたんですが、普通に男性のしゃべり声を解析してからボーカロイドエディターで調整しても、どうもいい感じにならないんですよね。
そういうわけで、裏声で女声っぽい音域でしゃべったデータを解析して使ったところ、当初よりは使えそうなデータになりました。そういうわけで、セリフ用のデータを作るときも、実際に使いそうな音域を考慮して収録したほうがよい結果になりそうです。
ちなみに、SONARという名前じゃなくなったCakewalk by BandLabとV-VOCALの組み合わせで説明してますが、Studio
OneとMelodyneの組み合わせでも同様のことができることを確認しています。最近のDAWなら何らかのピッチ修正機能がついていることが多いですし、ほかにも似たようなことが出来る組み合わせはあるのではないかと思います。しかし、これ全手動でやってる人たちってすごいな……。
それはそうと、ヘッドセットマイクを装着して、PCに向かって裏声で女性っぽい言い回しを録音している自分を第三者が見たら相当キモいだろうな、と思ったのですが、これは「DTMやる人はキモい」っていうことではないですよね、きっと(^_^;)。
SoundCloudにオリジナル曲をアップしています。現在の最新作は、1月1日にアップした『Mental Roughness』です。
そのほかいろいろ取りそろえておりますので、このサイトのMusicのページか、SoundCloudのぼくのページへどうぞ。
コメントをお書きください